About the Inference Utility
Public AI for countries
September 2, 2025
The Public AI Inference Utility is the public access point for public and sovereign AI models.
The Utility uses a fully-featured, open-source frontend and a deployment layer that runs on compute from public and private partners around the world. We offer stable, direct access to models built by national (and international) public institutions. Imagine a water or electric utility, but instead of H20 or electrons, you're getting inference on tap.
What you can do with it
Try using it: chat.publicai.co.
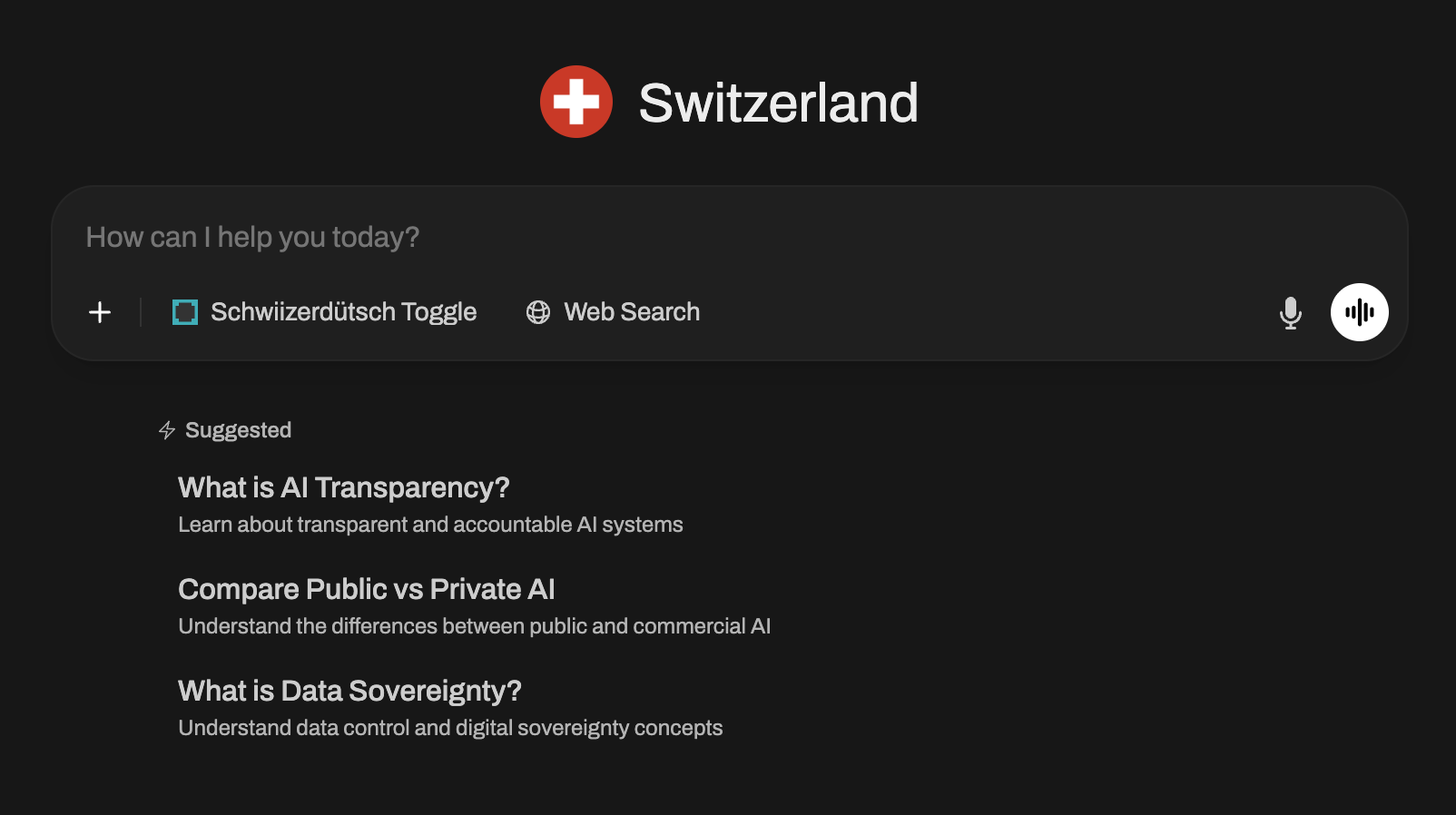
Some features you might not notice:
- Everything is open source! Inspect our frontend here and our app here (based on OpenWebUI).
- Multiple vetted models. Access Apertus from Switzerland as well as SEA-LION v4 from Singapore. More coming soon.
- National system prompts. Currently for Switzerland and for Singapore. Decide as a community what the system prompt should be.
- National knowledgebases - While logged in, try typing # in the chat to reference national RAG systems for Switzerland and Singapore. (Still experimental.)
- Search and tool usage - Integrated web search and tool plugins expand the base model's capabilities. Try the Schwiizerdütsch plugin, our German-speaking users love it.
- Privacy-first. By default, user prompts and outputs are not used for training or shared. Delete or export your chats at any time. Down the line, there will be opportunities to contribute to AI, but only if and when you want to.
- Public governance. Our funding, model selection, and operating principles are fully open.
How it works
The Inference Utility runs on a distributed infrastructure that combines an open-source frontend, a vLLM-powered backend, and a deployment layer designed for resilience across multiple partners. The frontend is a lightweight React/Tailwind interface. Behind the scenes, inference is handled by servers running OpenAI-compatible APIs on vLLM. These servers are deployed across clusters donated by national and industry partners. A global load-balancing layer ensures that requests are routed efficiently and transparently, regardless of which country's compute is serving the query.
Sustainability comes from blending different funding models. Free public access is supported by donated GPU time and advertising subsidies, while long-term stability is intended to be anchored by state and institutional contributions. For users who need higher availability or premium features, we plan to offer tiers that remain accessible while helping to cover operating costs.
Roadmap
After the Apertus launch, we hope to expand the Utility with new launch partnerships in countries like Singapore, Spain, and Canada. Other improvements: support for image models and multimodal queries, and more jurisdiction-aware handling to reflect different legal and cultural contexts. On the sustainability side, we are refining both the advertising-supported and utility-style business models, while testing "Plus" and "Pro" tiers that remain accessible (we'd like to experiment with models based on Wikipedia-style data contributions, though we might supplement that with subscription-based models). Longer-term, we want the Utility to support national data flywheels and nation-scale inference infrastructure.
Why it matters
Public and sovereign AI labs can build world-class models, but they often lack the compute and infrastructure to serve them reliably. Despite their awesome power, national supercomputing centers are not set up for 24/7 public inference, nor are they equipped to offer a user-facing service. The Utility solves this problem.
It also complements the open-source ML ecosystem by providing stable, transparent, and accountable access to open models—something that is currently only available from private APIs. The Inference Utility is a step towards a more open and accessible AI ecosystem. In many ways, it's trying to fill in the gaps in the existing open-source ecosystem.
Learn more
To learn more about the team behind the Utility, go to our about page.