Behind the scenes: how we shipped the Inference Utility with help from AWS Zurich and Intel
The first in a series examining inference and inference economics across the different partners contributing to public AI.
June 16, 2026

The Public AI Inference Utility originally got started when the Apertus team introduced us to AWS. Our first call brought together Josh and Joseph with Nicolas Jourdan, Malte Reimann, Milan Vopalka, and Swiss AI's Imanol Schlag and Mauricio Moncada. Nicolas joined from Frankfurt, Malte from Zurich. We were relatively new to the hosting experience, and Nicolas and Malte were extremely generous with their time helping us through the process and working through a calculation on just how many clusters we would need to support the Apertus launch. Special call out to Simone Pomata as well, who took us through a long tour of how to make sense of the AWS org-structure interface.
Early Architecture and the First Pods
Once the preliminaries were out of the way, the conversations shifted immediately into architecture. On Slack, Joseph and Nicolas compared diagrams and walked through tradeoffs: using Cloudflare instead of CloudFront + WAF, letting developers hit the Zuplo API directly, and keeping the routing layer simple enough to inspect under load.
Memorializing here part of our own learning process: we struggled with AWS–OpenAI compatibility quirks, and the documentation sent us through several loops: how to use Open WebUI, whether LiteLLM needed to be upstream or downstream of guardrails, and how to get Bedrock's safety features applied on the right side of the traffic path.
Meanwhile, Cognito introduced its own detours. Logout flow wasn't OIDC-compatible, so Joseph explored patching the Open WebUI Docker image, wiring a Lambda to fake the expected logout sequence, and working around SES's default email-verification quotas. Malte joined those threads too—debugging Cognito's rate caps, helping configure SES, and submitting quota requests when the defaults throttled us.
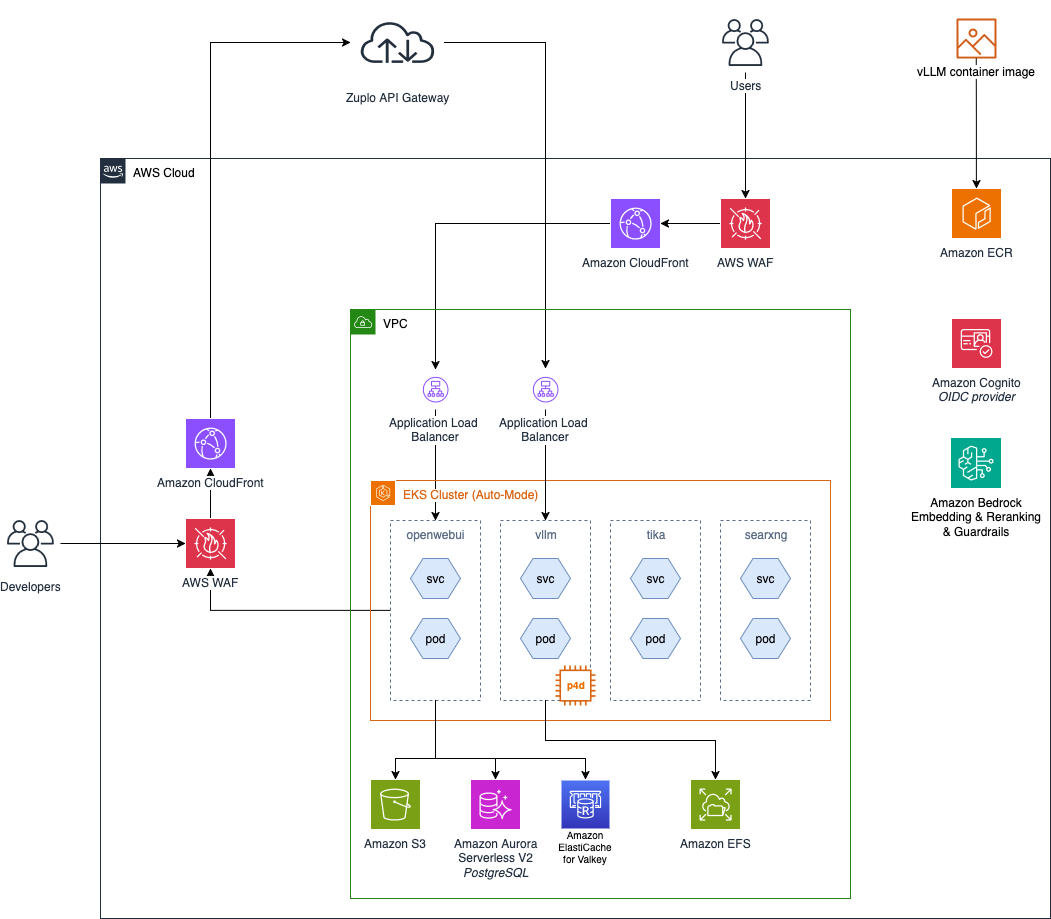
An early iteration of our architecture showing the AWS infrastructure powering Public AI
Guardrails, Routing, and the Zurich Pods
As we moved closer to serving real traffic, the Slack channel filled with the details that actually make—or break—a public deployment.
As we moved closer to serving real traffic, we moved on to the guardrail implementation. Nicolas walked Joseph through setting up Bedrock protections for PII, abuse, and prompt-injection filtering, with LiteLLM acting as the enforcement layer. He dropped full YAML samples for a namespace, service account, configmap, secret, and deployment, which we adapted almost verbatim.
The routing layer evolved alongside it. Joseph started testing custom auth in Open WebUI for rate limiting and per-user budgets in LiteLLM. Redis experiments followed: exploring whether it could handle routing, caching, or both; identifying what broke when requests spiked; fine-tuning the budget logic to avoid locking users out prematurely.
Our conversations with Nicolas and Malte produced the final plan: for three 8-GPU pods in Zurich—meaning about $124,000 in compute credits over 3 months—running a fully sharded Apertus 70B and a lighter 8B replica. Nicolas and Joseph traded notes on the right CPU/memory ratios, how to squeeze more throughput from the 8B model, and what a realistic concurrency target looked like.

The Launch and the Demo
Then we went live! Traffic ramped faster than expected. Nicholas and Malte spent a few late nights tracking throughput with us. And once the pods were online, every conversation served from Zurich began showing the small line:
"Served from Zurich on AWS infrastructure."
During the AWS Zurich event a few weeks later, the Apertus team wanted to demo Apertus live on stage. So that week, we shifted most of the traffic to Zurich (a significant portion of volume was being sent to other partnrs like Exoscale in Austria and Juelich Supercomputing Centre in Germany) so that Nicolas and Malte could show off the cluster. That was a pretty interesting learning experience.
After the Credits
The Apertus deployment, of course, didn't stop at the end of November. That's when we first began folding in the Intel-backed AWS nodes running in the same region. That transition is where Diego Bailón Humpert entered the scene. Where Nicolas and Malte had built the GPU stack for Apertus at launch, Diego brought together the Intel clusters that made sustained public inference possible—and scalable beyond Switzerland.

Diego worked across research institutes and cloud teams to stand up cost-effective CPU inference on Intel Xeon-based instances—tuned for the 8B-parameter class that most sovereign initiatives produce. The result wasn't a single model endpoint. It was a layer of Intel-backed clusters that has hosted EuroLLM, Spain's ALIA models, the Apertus 8B model, and a growing set of other open-source models from public institutions across the world.
Each addition followed the same pattern: open models on Hugging Face, production endpoints on the Inference Utilit. Diego's contribution was making that pattern repeatable—connecting the right hardware, the right regions, and the right serving configuration so each new sovereign model could land without starting from scratch.
Nicolas, Malte, and Diego wrote up the full architecture in a post on the AWS Partner Network blog. Take a look there for more of the technical details.
Sidebar: The 3×8-GPU Zurich Pods & Burn-Rate Model
Pod Layout
Each pod ran:
- 8×A100 GPUs
- A full 70B Apertus shard (with the 8B model on a paired replica)
- Local batching
- KV cache reuse
- Guardrails applied via LiteLLM
- A LiteLLM router with custom rate-limiting logic
Throughput Benchmark
We targeted concurrency by comparing against the Llama-3 launch:
- Meta reached ~5,000 concurrent users at peak
- Our realistic target was ~2,500 concurrent users
- This determined both the pod count and the credit request
Burn-Rate Components
- Idle-to-peak behavior: public traffic is lumpy; autoscaling suppression reduced wastage
- Batching: maintained ~70–80% GPU utilization without queue buildup
- Request composition: moderate lengths kept steady throughput
- Safety overhead: Bedrock guardrails added ~5–8% latency
Outcome
The credits lasted far longer than the initial projections. Batch efficiency, hybrid Intel routing, and careful traffic shaping all contributed. More importantly, the model gave us a real empirical grounding for the cost curve of public inference—something policy documents talk about abstractly, but engineers deal with directly.